


Author: Ujjwal Kumar Singh, Senior QA Engineer · 8+ years in enterprise QA · beinghumantester.github.io
Key takeaways
- AI will not replace testers — but it will make undocumented tester expertise visible and urgent to address
- There are two types of invisible testing work: genuine professional expertise, and organizational debt carried by people
- AI test generation tools cannot perform causal reasoning about system failures — this requires human mental models built over years
- The adaptive capacity testers exercise daily is the most undervalued competency in software engineering
- Organizations must document risk models and acceptance criteria before AI integration, not after
- Testers who make their judgment explicit become more valuable as AI capabilities increase
For years, software teams believed their testing processes were robust. In reality, many were functioning only because testers were quietly compensating for everything the process failed to capture.
When a requirement arrived without acceptance criteria, a tester asked the right questions. When an environment behaved unpredictably, a tester reran the suite and used judgment to determine which failures mattered. When a business rule existed only in someone’s memory, a tester found that person. None of this appeared in dashboards or sprint metrics. It simply happened, and the system looked stable because of it.
Now AI is entering testing workflows at speed. Teams are integrating LLM-based test generation, AI agents, and intelligent automation tools — many under genuine pressure to show results quickly. Systems that appeared to function smoothly are showing cracks. Not because AI introduced new problems. But because AI, unlike a skilled tester, cannot perform the human judgment work that was holding things together.
Most testing processes did not fail when AI arrived. They were already failing. AI simply removed the human layer that had been quietly making them work.
The Two Types of Invisible Testing Work AI Is Now Exposing
Before examining what AI is exposing, it is worth being precise about the work itself. Not all of it is the same kind, and conflating the two leads to the wrong conclusions.
Type 1: Genuine professional expertise
A tester reads a requirement and asks not just what it says but why it exists, who depends on it, and what failure would cost the business. They identify the edge case that matters not because it is in the documentation but because they remember a production incident from eighteen months ago. They make risk prioritization decisions continuously and implicitly. These decisions require contextual understanding that cannot be derived from the text in front of them. This is expert judgment, and it represents real and hard-won value.
Type 2: Organizational debt carried by people
Rerunning flaky tests to filter noise that a stable environment would never produce. Manually interpreting CI failures because the pipeline lacks observability. Compensating for missing acceptance criteria that should have been written before development began. This work is also undocumented but it is not expertise. It is the cost of systemic problems that teams resolved by finding capable people and relying on them to absorb the friction.
What resilience engineering calls this
Adaptive capacity is the human ability to keep imperfect systems functioning by recognizing and responding to conditions the system’s designers never fully anticipated. Testers have been exercising adaptive capacity for years, quietly, professionally, and without it ever appearing in a job description.
In many teams, the better testers become at exercising that capacity, the less visible the underlying problems become — and the less urgency organizations feel to fix them. AI is removing that option by removing the adaptive layer entirely.
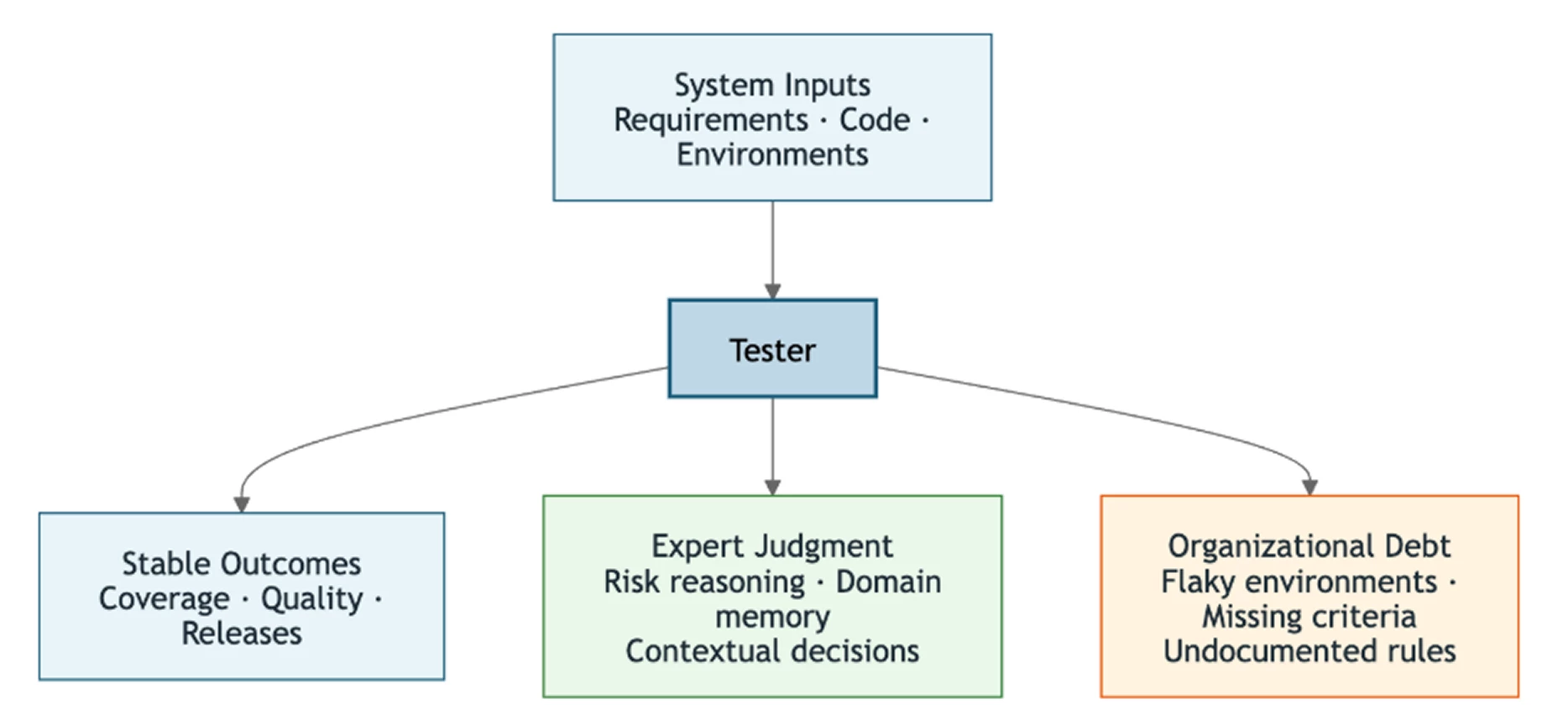
AI is exposing both types of work simultaneously. The risk is that organizations respond to one without distinguishing it from the other — celebrating the expertise while continuing to ignore the structural gaps beneath it.
Why AI Cannot Replicate Human Tester Judgment
Large language models are genuinely powerful at recognizing patterns across explicit inputs: written requirements, existing code, documentation, and historical test data. Given structured and high-quality inputs, they produce outputs with speed and consistency that no individual tester can match.
But the judgment a tester exercises when deciding which risks matter most is a different kind of reasoning entirely. Large language models optimize for the statistical probability of token sequences. Testing decisions, by contrast, are fundamentally risk optimization problems. They require reasoning about business impact, user behavior, system architecture, and historical failure patterns simultaneously. That is risk prioritization under uncertainty, and no amount of additional training data changes the nature of what the model is optimizing for.
The deeper limitation: testers reason from mental models of how a system behaves under stress — how failures propagate, where retry logic breaks down, which degraded states are recoverable. Large language models reason from patterns in text describing that system. Those are not the same source of knowledge.
A tester thinks: “If this gateway fails, the retry queue will fill, and then order reconciliation will break downstream.” That is causal reasoning about system behavior. It cannot be derived from documentation that was never written.
A Real-World Example: What Happens When AI Meets Undocumented Risk
The scenario
A team integrates an AI test generation tool into their workflow. The results arrive quickly. Over a hundred tests are generated from the backlog in under a minute. Coverage metrics look promising. The team is encouraged.
A senior tester reviews the output and notices something: every generated test assumes the payment gateway responds successfully. There is not a single scenario covering gateway timeouts, partial failures, or retry behavior. The tester flags this immediately — not because they consulted the documentation, which says nothing about it, but because they remember a production incident two years earlier when a gateway timeout caused silent order failures that took three days to detect.
What the tester saw that the AI could not
The AI had no way to know. The requirement described the happy path. The user story contained no failure handling. The training data held no record of that incident. The tool did precisely what it was designed to do: generate tests from the inputs available to it. The gap was not in the tool. The gap was in everything the tool could not see.
When the tester investigated further, the gap was wider than a single missing test:
- No monitoring alert was configured for partial gateway responses
- The retry policy in the codebase handled network timeouts but not partial authorization codes
- The incident runbook mentioned the gateway by name but said nothing about degraded states
- The tester was the only place in the organization where the full shape of that absence was understood
The tester who reviewed that output was not correcting AI. They were making visible a risk the organization had stored only in human memory and nowhere else.
The pattern repeats across every AI adoption scenario
Teams using AI-powered automation agents discover that their application’s testability — unstable selectors, inconsistent identifiers, frequent UI changes — was something testers had been navigating through adaptation and judgment rather than documented solutions. Teams using AI to analyze CI failures discover that the pipeline’s reliability was something testers were filtering manually. In each case, the AI did not introduce the problem. It stopped compensating for it.
Recognition Is Not Reform: What Organizations Must Actually Do
The natural organizational response to these revelations is to validate the testing function. That validation is earned. But recognition without structural change accomplishes very little.
What must become explicit
Valuable tester judgment — the risk reasoning, domain expertise, and contextual decisions that make testing meaningful — needs to be made explicit and transferable. That means:
- Documented risk models: which failure modes matter most and why, based on past incidents and business impact
- Structured acceptance criteria: written before development begins, not derived from it
- Test strategies with reasoning: documents that articulate not just what is tested but why those choices were made
- Institutional knowledge capture: treating testing knowledge as an organizational asset rather than a personal attribute
What must be eliminated
Organizational debt — flaky environments, undocumented systems, requirements that arrive without definition — needs to be eliminated rather than accepted as the background condition of how testing works. Organizations that respond to AI adoption by appreciating testers more while leaving systemic weaknesses intact have learned the wrong lesson. They have validated the symptom and ignored the cause.
What the Future of Testing Expertise Looks Like
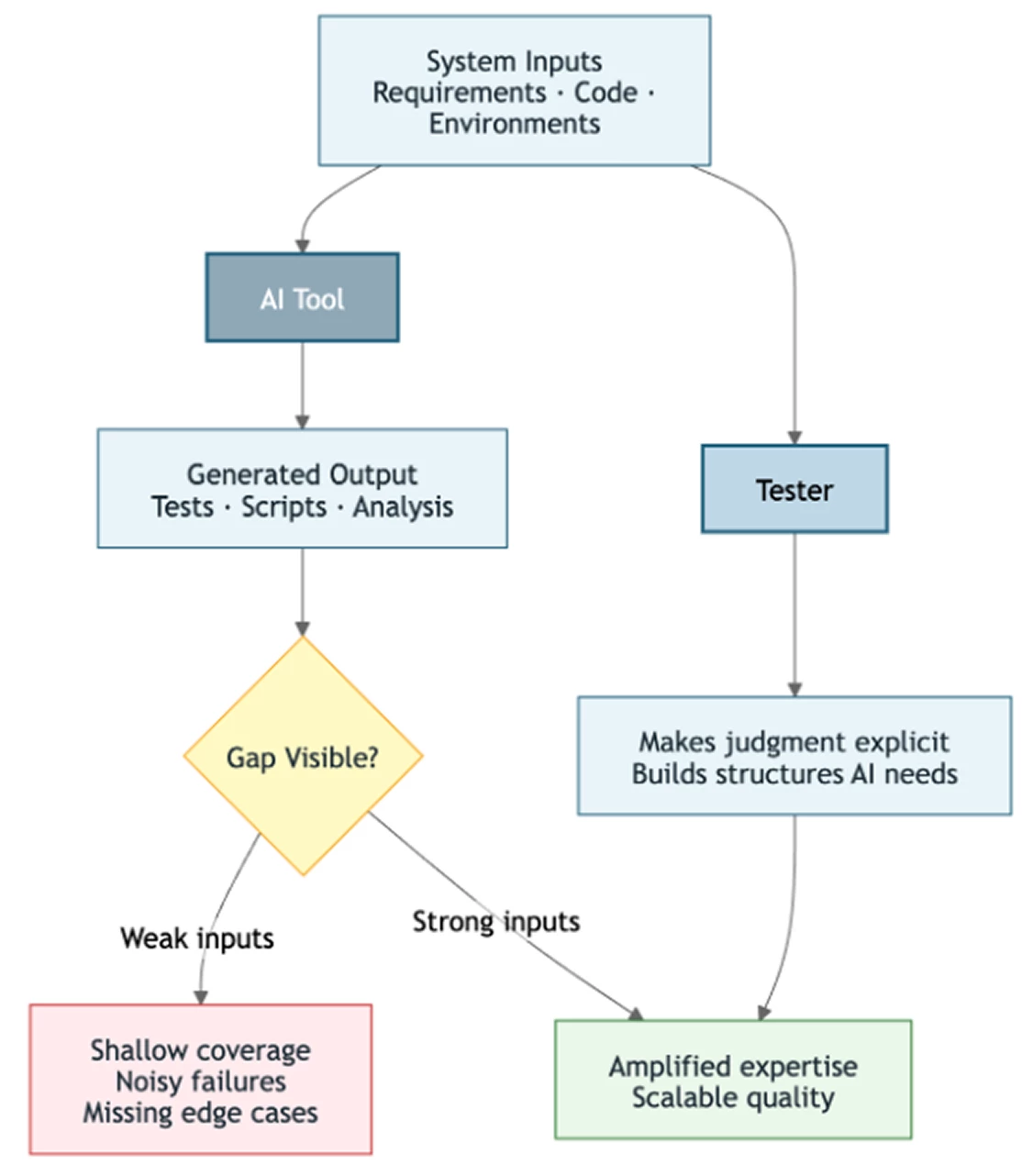
If the undocumented expertise of testers can be made explicit — if risk models can be captured, domain knowledge preserved, and test strategies articulated clearly — then AI can assist in applying that expertise in ways that genuinely scale.
An AI tool working from a well-constructed risk model and clear acceptance criteria is a fundamentally different proposition than an AI tool working from vague user stories and undocumented assumptions. The former amplifies expertise. The latter exposes its absence.
The key distinction
The tester who absorbs ambiguity is maintaining the system. The tester who removes ambiguity is improving it. That tester becomes more valuable as AI capability increases, not less.
What this means for testers right now
Every place an AI tool struggles in your workflow is a precise indicator of where your organization has been relying on individual expertise instead of building systems that preserve it. That struggle is a map. Follow it.
What this means for engineering leaders right now
The question is no longer whether testers are valuable. AI adoption has answered that. The question now is what gets built with that knowledge. The real impact of AI in testing is not automation. It is forcing organizations to confront the knowledge they never captured, the systems they never documented, and the expertise they relied on without ever making it transferable.
Frequently Asked Questions
AI will not replace software testers, but it is fundamentally changing what testers do. AI test generation tools expose gaps in documentation and process that skilled testers have been quietly compensating for. Testers who document their expertise — risk models, domain knowledge, contextual judgment — become more valuable as AI scales, because AI amplifies explicit knowledge but cannot replicate undocumented human judgment.
Invisible work in testing refers to the undocumented judgment testers exercise to keep software systems functioning despite incomplete processes. It falls into two categories: genuine professional expertise (risk prioritization, domain knowledge, causal reasoning about system failures) and organizational debt absorption (compensating for flaky environments, vague requirements, and undocumented systems). AI cannot perform either type without this work being made explicit first.
Large language models optimize for statistical patterns in text. Tester judgment is fundamentally risk optimization under uncertainty — requiring reasoning about business impact, system architecture, user behavior, and historical failure patterns simultaneously. A tester who remembers a production incident from two years ago can design tests for that failure mode. An AI tool has no access to that undocumented incident and will generate tests only from explicitly written requirements.
Adaptive capacity is a concept from resilience engineering: the human ability to keep imperfect systems functioning by recognizing and responding to conditions the system’s designers never anticipated. In software testing, testers exercise adaptive capacity constantly — rerunning flaky tests with judgment, interpreting ambiguous requirements, compensating for undocumented business rules. AI removes this adaptive layer, making underlying problems visible for the first time.
Treat AI adoption as a documentation forcing function. Before integrating AI testing tools: (1) document risk models explicitly — which failures matter most and why; (2) establish structured acceptance criteria before development begins; (3) write test strategies that explain not just what is tested but why; (4) eliminate systemic issues like flaky environments rather than relying on testers to absorb them. AI amplifies documented expertise and exposes the absence of undocumented expertise.
When AI tools enter testing workflows, they reveal that many processes were not as robust as they appeared. AI cannot ask clarifying questions, remember past incidents, or apply judgment to ambiguous requirements — so gaps that testers quietly filled become visible. Common revelations include: unstable test selectors maintained through tester adaptation, CI failures filtered manually rather than by observability tooling, and test coverage that assumed stable environments that were actually fragile.




