



Data Quality: The Foundation of AI/ML Success
In the rush to adopt AI and machine learning, many organizations overlook one crucial foundation – the quality of the data feeding those models. AI systems are only as good as the data they learn from. Faulty or biased data can quickly derail AI initiatives, embedding errors and biases that ripple through predictive models and business decisions. The hidden costs of bad data are immense: analyst firms estimate that poor data quality costs businesses trillions of dollars each year. These costs come in many forms – from AI models making flawed recommendations, to regulatory penalties from inaccurate reports, to countless hours wasted troubleshooting data issues. In short, if your AI/ML projects are built on shaky data, the outcomes will be just as unreliable. Quality engineering in the AI era must treat data itself as a critical asset to be tested and validated, not assumed correct by default.
The Challenge: Why Manual Data Validation Falls Short
Many QA teams today struggle with ensuring data integrity because traditional testing methods can’t keep up with modern data pipelines. Data is growing exponentially, moving through countless systems, and changing constantly – far too much for any manual “stare and compare” approach to cover. In complex pipelines, data may flow from CRM systems to ETL jobs to data lakes and AI training sets, with each handoff introducing potential errors or transformations. Catching issues by manually spot-checking databases or reports is like finding a needle in a haystack. In fact, today’s digital environments are so dynamic and interconnected that relying on manual data testing is widely recognized as untenable. End-to-end tests built by hand often break with any change, and they’re slow to execute at the scale of big data. The bottom line: purely manual data validation doesn’t scale. QA and data teams need a way to automatically verify huge volumes of data across disparate systems, continuously and quickly.
Moving to Continuous, Automated Data Validation at Scale
Given these challenges, leading organizations are shifting from reactive, manual checks to a proactive, automated strategy for data quality. Instead of waiting for a data issue to surface in a broken dashboard or a biased model output, the idea is to catch problems early – as soon as data is collected, transformed, or loaded through the pipeline. This “test early, test often” philosophy mirrors the shift-left movement in software testing, now applied to data. As one industry expert put it, modern businesses need automated, end-to-end data integrity solutions to ensure their AI models are built on a solid foundation. By validating data at every stage of its journey, teams can detect anomalies like missing or corrupt values, schema mismatches, or logic errors long before they wreak havoc downstream. Crucially, this continuous approach doesn’t just react to known issues – it actively monitors for unexpected data changes or quality drift, providing QA teams with confidence that the data pipeline itself is trustworthy. In practice, achieving this level of oversight requires the right tooling built for data validation at scale.

How Tricentis Data Integrity Enables Scalable Data Quality Testing
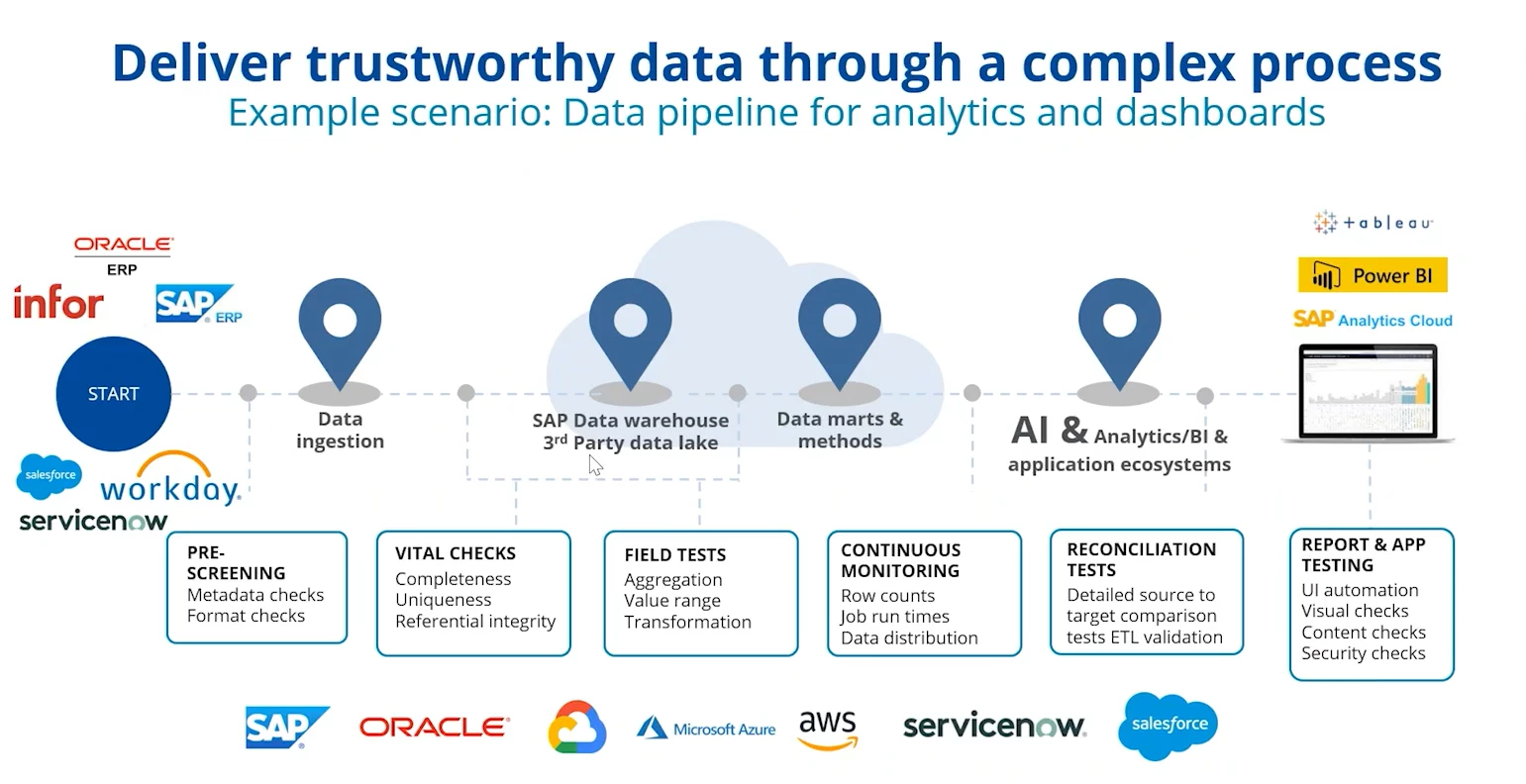
Tricentis Data Integrity (TDI) was designed to address exactly these data quality challenges in enterprise environments. It brings the discipline of software test automation to the world of data. In essence, Tricentis Data Integrity enables completely automated end-to-end data testing across all layers of your data ecosystem – from the moment data enters a staging area or data lake, through transformations in data warehouses, to the final BI reports or AI model inputs. This end-to-end coverage means QA teams can verify, for example, that a million records extracted from a source system exactly match what's loaded into a target system, or that a critical business rule holds true across every record in a dataset. All of this happens continuously and at scale, far beyond the throughput of any manual effort.
Practically, Tricentis Data Integrity provides a structured approach to catch errors before they impact AI/ML outcomes. It offers out-of-the-box templates and wizards for common data tests, so teams can quickly set up automated checks without reinventing the wheel. For instance, a pre-screening test can instantly flag missing values, duplicates, or misformatted fields as soon as data is loaded, ensuring upstream data is clean. Reconciliation tests can automatically compare data from source to target (even across different file formats or databases) to confirm that no records were lost or altered in transit. The tool also supports business rule tests (sometimes called profiling tests) to verify data makes sense in context – e.g. a test to ensure no active customer accounts have an impossible combination of attributes. By building these validations into the pipeline, Tricentis Data Integrity enables what is effectively a continuous audit of your data’s accuracy. As the Tricentis team notes, the solution provides continuous, automated testing to keep data pipelines reliable even as systems change, and end-to-end visibility so that errors introduced during complex ETL processes are immediately caught.
Equally important, TDI integrates with existing QA workflows and toolchains. QA engineers can incorporate data tests into their regular test plans and CI/CD pipelines, just as they do for application functional tests. This means data quality checks run automatically with each new data load or pipeline update, providing rapid feedback. Instead of a separate silo, data integrity testing becomes part of the continuous testing culture – a natural extension of quality assurance into the realm of data. By scaling data validation in this way, teams significantly reduce the risk that bad data will slip through and cause AI model misbehavior or analytic errors. In effect, Tricentis Data Integrity lets QA teams move beyond the limits of manual data checking and apply the power of automation to ensure trustworthy data at every step.
Reducing Risk and Cost by Ensuring Reliable Data Pipelines
The payoff from this rigorous approach to data quality is clear: fewer nasty surprises and more confident AI outcomes. When data issues are caught early (or prevented entirely), organizations avoid the hidden costs that poor data quality would otherwise incur. Consider the scenarios: an AI-driven recommendation system that learned from skewed data might push the wrong products, hurting revenue, or a financial report built on inconsistent data could lead to compliance fines. By deploying continuous data integrity checks, such failures can be averted before they ever reach a decision-maker or a customer. Studies have found that bad data not only slows down innovation but directly leads to financial losses – on a massive scale. With automated data integrity testing in place, companies dramatically cut down the time and money spent diagnosing faulty data pipelines or retraining models due to avoidable errors. In fact, organizations embracing tools like TDI often find that ensuring data quality upfront is far cheaper than cleaning up problems later. It’s the classic testing principle applied to data: the earlier you find a defect, the less it costs to fix. By establishing reliable data pipelines, QA teams enable AI/ML initiatives to proceed with a solid foundation, reducing rework and boosting trust in AI-driven results.
Quality Engineering’s Next Evolution: Data as a First-Class Asset
The rise of AI and data-driven development is transforming the role of QA and testing. Quality engineering is no longer just about validating application code or user interfaces – it now extends to data itself. High-performing teams treat data with the same rigor as any software artifact, subjecting it to version control, automated tests, and continuous monitoring. In this new paradigm, QA professionals collaborate closely with data engineers and analysts, bringing proven QA methodologies to data pipelines. Tools like Tricentis Data Integrity fit perfectly into this shift: they empower QA teams (not just DBAs or data scientists) to define and execute data quality checks at scale, using automation to amplify their reach. Ensuring data integrity becomes an integral part of delivering a quality software product or analytics solution. This evolution is driven by necessity – with AI models influencing critical business decisions, data is effectively part of the product. Just as no one would deploy untested code to production, forward-looking organizations won’t deploy untested, unvalidated data into AI models. As the Tricentis blog emphasizes, companies that succeed with AI aren’t those with the most data, but those with the best, most trustworthy data.
In practice, embracing data quality in QA means building continuous data checks into the development lifecycle. It means adopting platforms like TDI to automate those checks across heterogeneous systems – from legacy databases to cloud data lakes – and scaling your data validation as your data grows. By doing so, QA teams become guardians not just of application quality, but of data fidelity. This is a natural extension of the QA mission to mitigate risk and ensure reliability. It’s also increasingly part of the job: as AI/ML initiatives expand, QA professionals who can speak to data testing are invaluable. Tricentis Data Integrity supports this evolution by making comprehensive data validation feasible and efficient for QA teams, allowing them to focus on what matters most – delivering insights and AI-driven features that the business can trust.
Conclusion: Data Integrity as the Key to AI-Ready Quality
AI and ML hold enormous promise for speed, insight, and innovation, but they will only fulfill that promise if built on a bedrock of high-quality data. For the QA and testing community, this is an opportunity to expand our impact – ensuring not just that software works as intended, but that the data driving our intelligent systems is sound. Scaling beyond manual data validation to a continuous, automated approach is now a best practice for any serious AI/ML initiative. Tricentis Data Integrity provides a powerful solution to implement this practice, helping teams turn data integrity from a vague concern into a well-managed aspect of the quality engineering process. By catching data errors before they become AI failures, we reduce costly rework and safeguard the value of analytics. Ultimately, incorporating data integrity testing into our QA strategy means we can deliver AI/ML projects with confidence, knowing that the insights and predictions they produce rest on solid, verified data.
This article was inspired by a webinar and a blog post.To explore the topic further, watch “The AI/ML journey: Preparing your organization for transformation” on-demand for an expert-led discussion on this topic.
You can also read the article “The hidden costs of bad data: Why AI needs data integrity” for more insights.

