



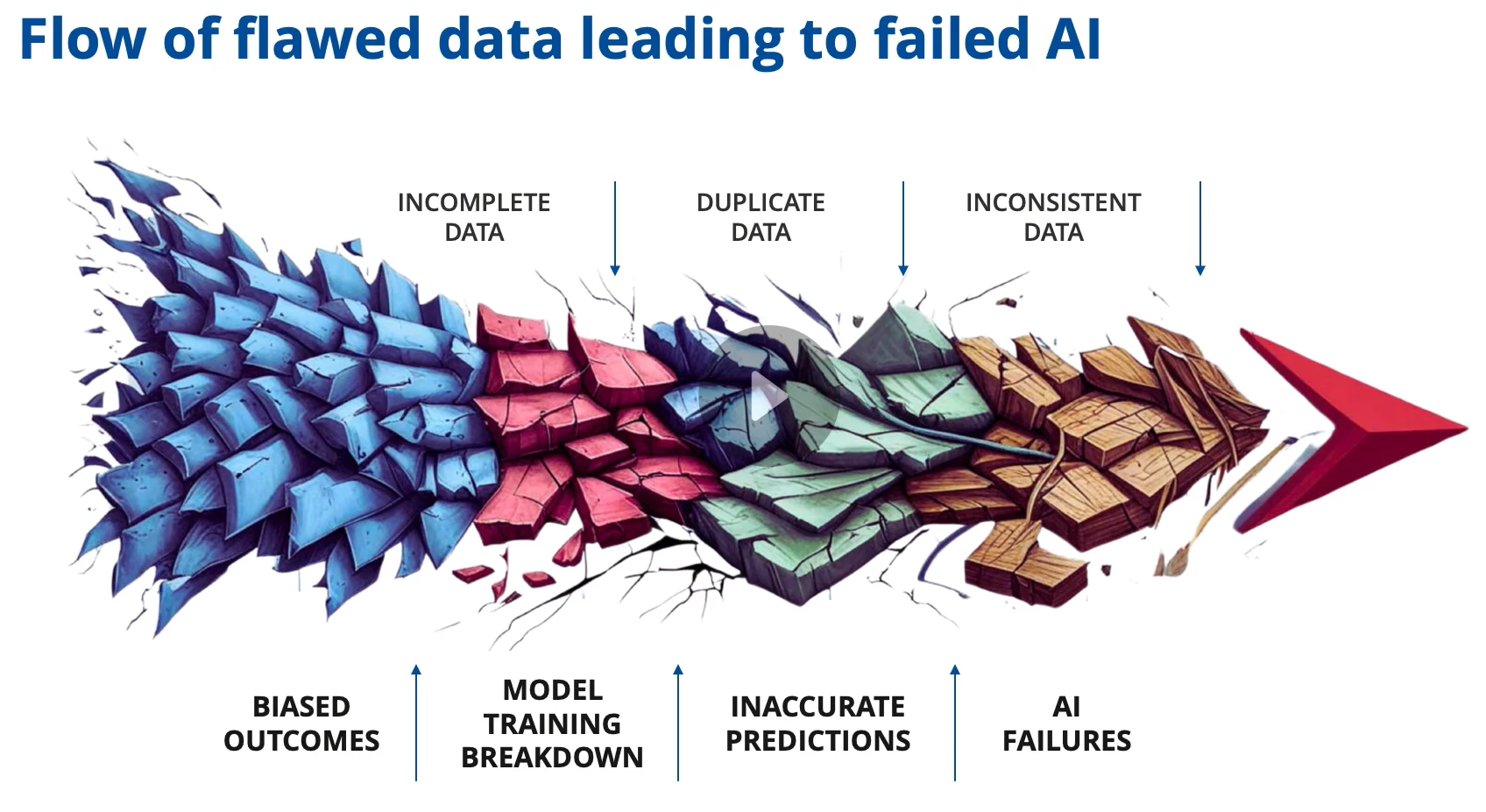
The Hidden Challenge Behind AI Success: Data Quality
Everyone is excited about the potential of AI and machine learning to transform business processes. But as organizations rush to adopt AI – from predictive analytics to intelligent assistants – a sobering reality has emerged: most AI initiatives fail to deliver value, and poor data quality is often the number-one culprit. Gartner famously estimated that 85% of AI projects fail largely due to erroneous or insufficient data. In other words, “garbage in, garbage out” holds especially true for AI. No matter how advanced an AI model is, it’s only as smart as the data feeding it. For AI to provide truly valuable insights, businesses must first ensure their data is complete, accurate, and trustworthy. Clean data leads to smarter AI, and achieving that level of data quality requires a disciplined focus on data integrity.
Data integrity means that data remains consistent, correct, and reliable throughout its lifecycle – from when it’s generated or migrated, through transformations and storage, and ultimately to when it’s used for decisions. In practice, this translates to rigorously validating data at every step. This is not a one-time effort; it’s a continuous process. Many companies learn this the hard way. They assume AI is a plug-and-play magic bullet, only to find that their shiny new AI systems are drawing the wrong conclusions from messy data. As one industry expert quipped, today’s AI copilots often perform at the level of an intern – not because the AI technology is inherently limited, but because the AI doesn’t know where all the data is or that some data is incomplete. The result? Incomplete analysis and unreliable recommendations. To avoid that outcome, organizations need to treat data quality as a first-class priority in any AI project. Business leaders certainly don’t budget for bad decisions – they assume the data driving AI-powered decisions is correct. It’s up to QA professionals and data teams to make that true by instilling robust data integrity practices.
Why Data Integrity Matters – Especially in Complex SAP Landscapes
Ensuring data integrity is critical for any enterprise, but it’s especially vital for large SAP-centric organizations (“SAP shops”) undergoing digital transformation. These companies often deal with complex data pipelines – for example, migrating data from on-premise SAP ERP into cloud data lakes or warehouses, integrating SAP data with other enterprise systems, and feeding analytics tools like SAP Analytics Cloud or even AI-driven copilots. In such environments, even a small data glitch can have huge business repercussions. A stark example comes from a retail company in Florida that updated a software system in their SAP ecosystem: a tax calculation field’s precision was accidentally changed from two decimal places to four. This seemingly minor data error went unnoticed for weeks, but it cost the company several million dollars in mis-billed taxes before anyone realized something was wrong. The issue eventually landed on the CEO’s desk, and it took the team additional weeks to track down the root cause – an error that could have been caught in minutes with proper data validation checks.
Such incidents underscore that bad data can directly translate into financial loss, compliance risk, and damaged trust. For organizations running SAP, which often supports core finance and operations, the stakes are especially high. Data integrity issues might lead to faulty inventory levels, incorrect financial reports, or AI-driven forecasts that are wildly off target. Unfortunately, traditional testing approaches haven’t always kept up with these data challenges. Many QA teams still focus primarily on application functionality (e.g. testing that an SAP transaction works) and assume the data is “someone else’s problem.” But when you’re aiming to be AI-ready, data is very much a QA concern. QA and testing professionals need to expand their purview to include data quality validation as a key part of quality assurance.
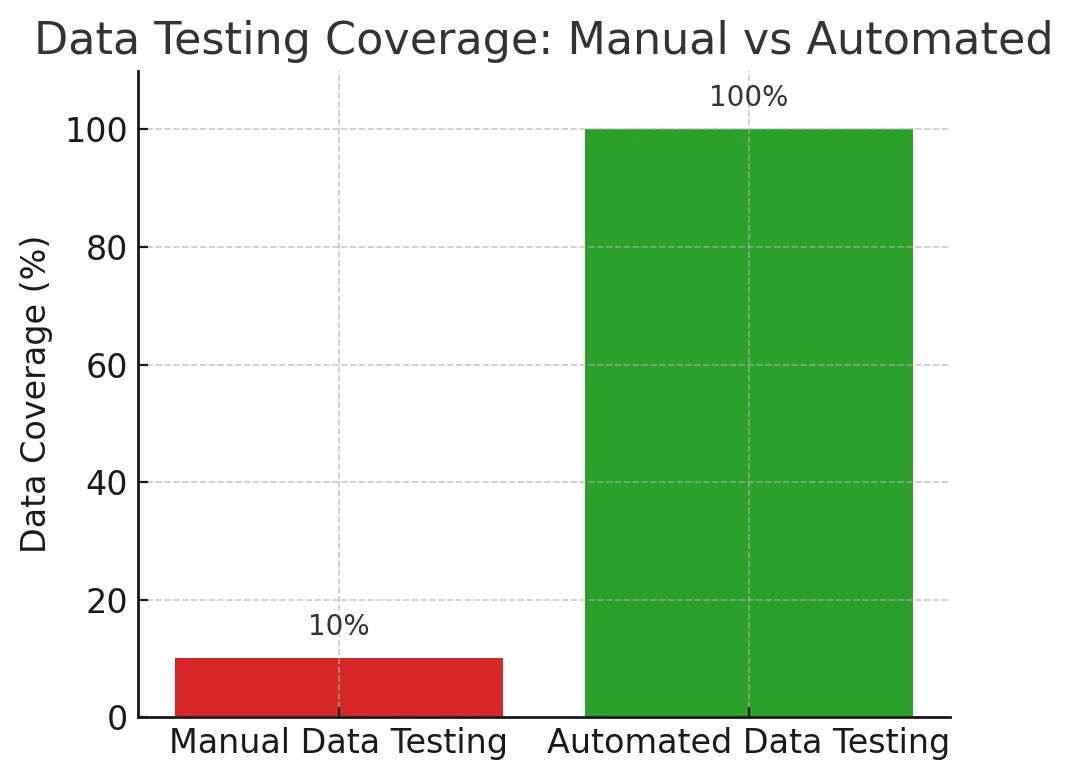
The problem is that manual data testing doesn’t scale to the volume and velocity of modern enterprise data. In one case, a company attempted to validate a large data migration (ingesting point-of-sale data into a data lake for analytics) by assigning a team of people to write SQL queries and do manual “stare and compare” checks between source and target. The result? Eight full-time analysts writing multi-page SQL scripts were only able to scratch the surface of the data despite working long hours. Important errors slipped through undetected. This is hardly surprising – when data tables have millions of records, humans simply can’t comprehensively verify each one. Manual, Excel-based approaches are painfully slow and leave dangerous gaps. As the complexity and volume of data grow, the old ways of spot-checking a tiny sample in spreadsheets become woefully inadequate. QA teams run the risk of giving a project a “pass” based on a 5% data sample, not realizing the other 95% hides critical errors.
For SAP-driven businesses, another challenge is the heterogeneity of the data landscape. You might have data flowing from SAP ECC or S/4HANA into a Snowflake warehouse, then into an SAP Analytics Cloud dashboard, and even into AI models. Multiple technologies (SAP and non-SAP) are involved, and data can easily become inconsistent or lost in translation. Without rigorous checks, a report in your BI tool might be pulling incorrect figures, or an AI-powered assistant might be drawing from outdated or wrong data sources. (One horror story involved an AI system unknowingly scraping revenue numbers from an employee’s email signature – obviously not the “single source of truth” you’d want!) These scenarios highlight why data integrity solutions have emerged as a crucial safeguard. They act as a watchdog across the complex data supply chain, ensuring that data remains accurate and consistent from end to end.
Best Practices for Achieving Data Integrity at Scale
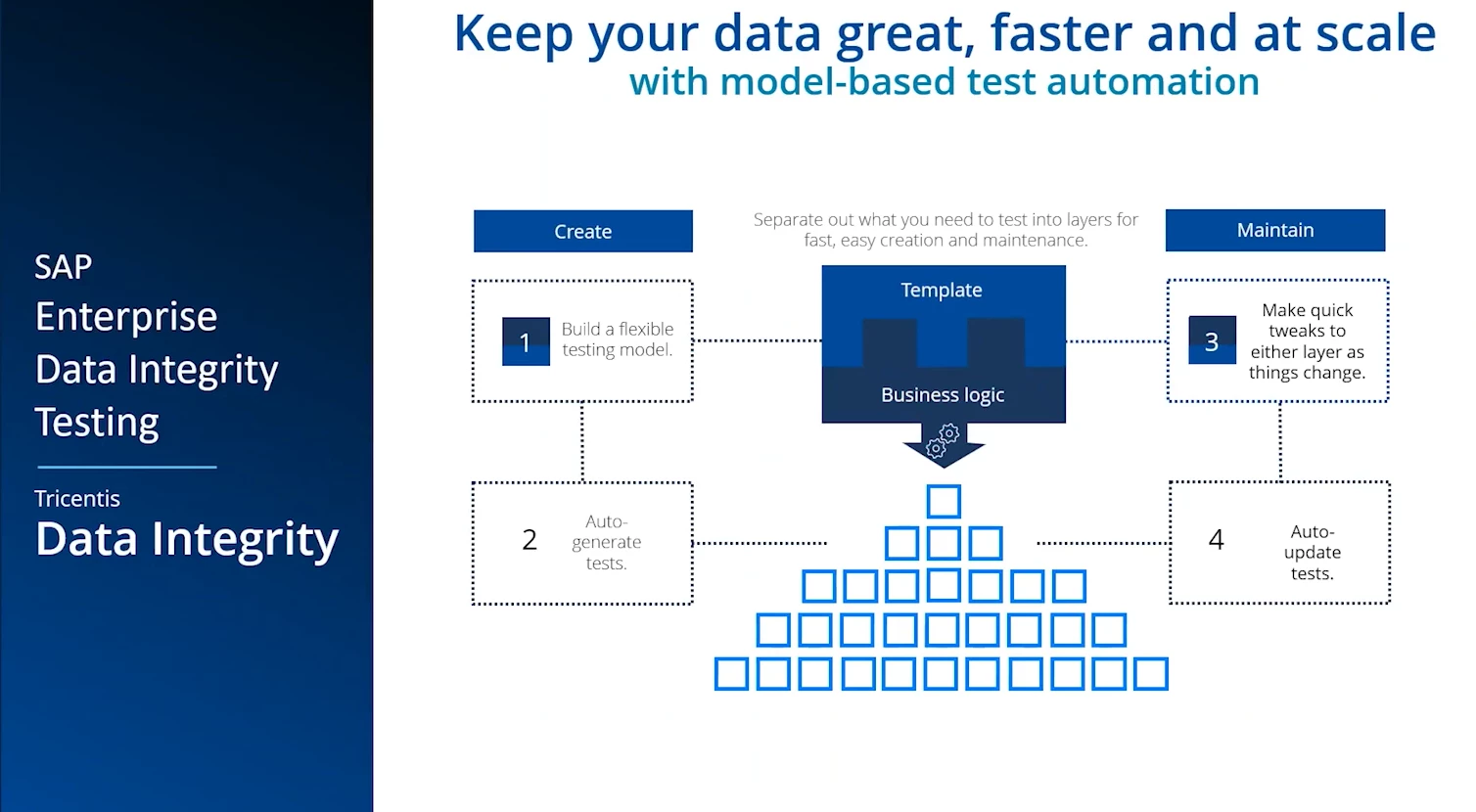
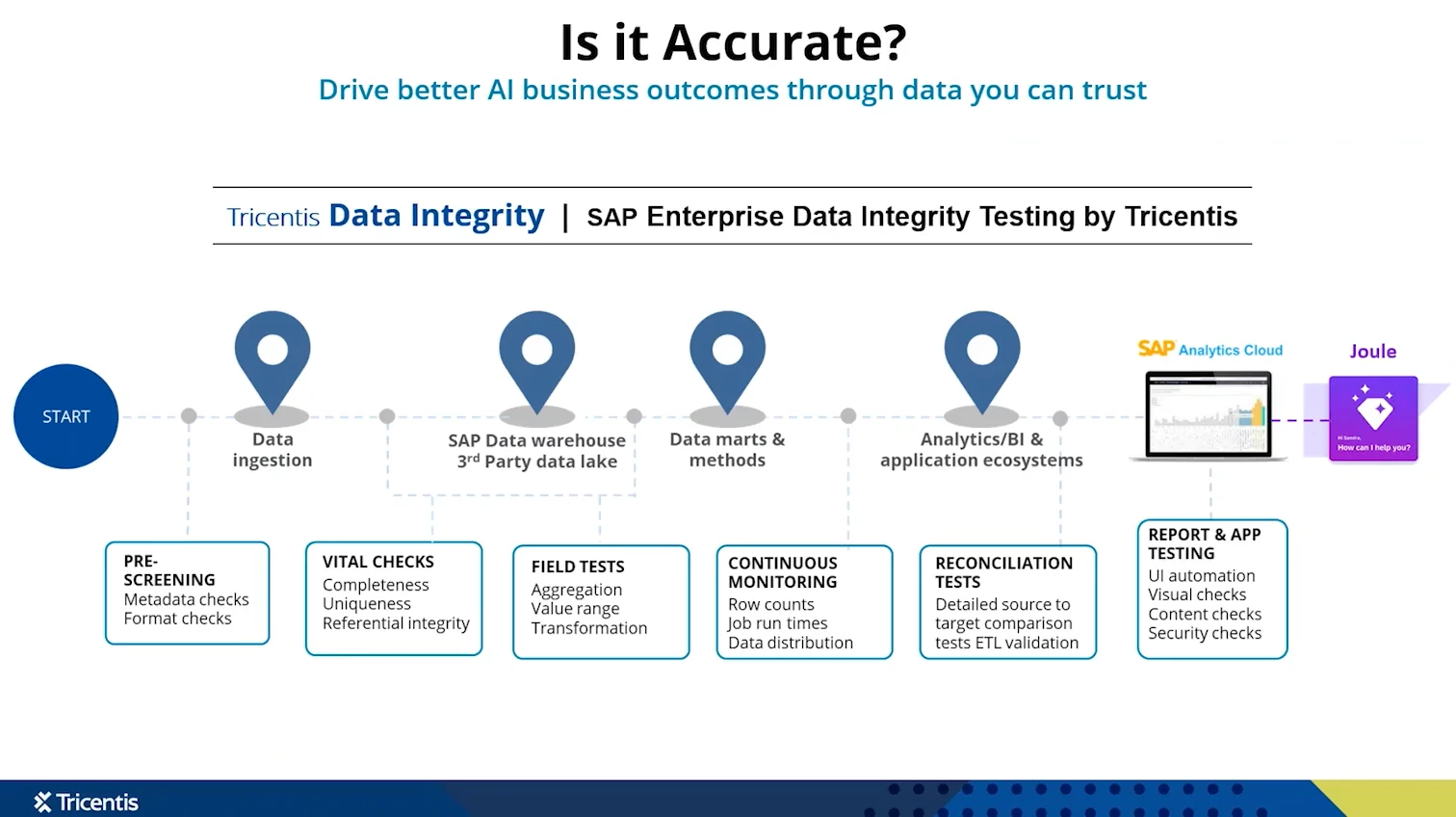
How can QA professionals and data teams tackle the data quality challenge? The answer lies in end-to-end, automated, continuous data testing. This approach borrows the discipline of software testing and applies it to data pipelines. Instead of ad-hoc manual checks, organizations are implementing layered automated tests at each stage of the data journey, often using specialized tools to manage and execute these tests. Here are some best practices and key components for maintaining data integrity at scale:
-
Validate data before it enters your core systems (Pre-screening): Start by verifying raw data files or inputs as soon as you receive them. For example, if third parties send you CSV or JSON files to load into SAP or a data lake, set up automated checks on those files’ metadata and format. Ensure each file is correctly structured, all required fields are present, and values are in expected ranges/types. Catching malformed data upfront prevents “garbage” from ever entering your databases. (This is exactly what one large bakery company did during their SAP cloud migration – they screened incoming data files for issues before loading them, saving countless headaches later.)
-
Use vital checks on the data content: Once the data is in a staging area or database, run automated tests on the content itself. These include checks for completeness (no records or values missing), uniqueness (no duplicate primary keys, for example), and referential integrity (foreign keys correctly reference parent records, etc.). Essentially, ensure the data makes sense and is consistent within itself. In a sales orders dataset, for instance, you’d verify that every order record has a valid customer ID that exists in the customer table. These sanity checks at the field and record level can catch issues like truncated values, duplicates, or mismatched codes early in the pipeline.
-
Reconcile data across systems: As data moves from a source system (say, an SAP module or legacy system) to a target (like a cloud warehouse or new SAP instance), perform reconciliation tests to ensure nothing was lost or altered unexpectedly. Automated reconciliation can be as simple as comparing record counts and key totals, or as granular as a row-by-row comparison between source and target tables. Did all 1,000,000 records that were supposed to migrate actually arrive in the target? Do financial totals match to the penny after a transformation? Reconciliation testing will flag any discrepancies in migration or integration processes. This is crucial during SAP migrations (e.g. moving to S/4HANA or to cloud) where losing or corrupting even a tiny percentage of data could be disastrous. The goal is that by the time data lands in a data warehouse or an AI model, it’s a faithful copy of the source, just in the new format.
-
Extend testing to the analytic layer (reports and AI outputs): Modern data integrity doesn’t stop at the database. It also involves testing the UI and reports that end-users see, as well as the outputs of AI models. For example, if you have a dashboard in SAP Analytics Cloud or PowerBI, you can automate a comparison between the dashboard’s figures and the source data in the warehouse to ensure the visualization accurately reflects the underlying data. Similarly, if an AI-driven “copilot” tool is meant to fetch data (like sales forecasts), you should verify that it’s pulling from the correct, curated data sources – not some rogue spreadsheet or email. By leveraging automation at the UI level (e.g. using scripts to mimic a user and validate on-screen values), you ensure that the last mile of data delivery is as error-free as the pipeline feeding it. This end-to-end view, from raw data to on-screen insight, is the essence of true data integrity testing.
-
Make it continuous and proactive: Perhaps most importantly, integrate these data tests into a continuous monitoring regime. Data integrity is not a one-and-done checkpoint; it’s an ongoing process, much like continuous integration/continuous delivery (CI/CD) in software. As data keeps flowing (which in an AI era, it constantly does), schedule these tests to run automatically – nightly, hourly, or in real-time as appropriate. Continuous data integrity monitoring means that the moment something goes awry in the data pipeline, you get alerted and can address it before it snowballs into a bigger problem. It shifts testing from reactive (finding problems weeks later) to proactive (catching them in hours or minutes). Modern data integrity platforms even provide dashboard and risk reports that show your data quality coverage and where any failures occurred, so the team has full visibility into the health of data across the enterprise at all times.
By following these best practices, QA and data teams can jointly build a safety net that guarantees reliable data for AI and analytics. The technical specifics might vary – one team might use a specialized data testing tool with out-of-the-box test templates, while another might script custom queries – but the overarching strategy is the same: test your data like you test your code, at every critical point, with automation and clear success criteria. This approach brings the discipline of software QA to the data world, which is exactly what’s needed to prevent AI from running on faulty inputs.
Real Results: Better Coverage, Faster Testing, Fewer Surprises
Adopting continuous, automated data integrity practices can sound like a lot of work – but the payoff is enormous. Organizations that have implemented these practices report significant improvements in both efficiency and risk reduction. A standout example is Flowers Foods (a large baked goods company) during their SAP cloud transformation. Their team replaced cumbersome Excel-based data checks with an automated data integrity solution. The results were dramatic: they achieved 100% coverage of their data in testing (up from only partial sampling before) and accelerated their data validation cycles by 3×. In other words, what used to take days of manual effort now runs in a matter of hours, and every single record is validated. Many other organizations report similar gains – it’s common to see data quality checks that used to cover maybe 10% of data now cover >90% or 100%, and test execution that used to take weeks shrinks to hours or minutes. Increased coverage and speed go hand in hand.
To appreciate the impact, consider the earlier example of the Florida company with the tax-calculation error. Before, it took them weeks to notice and more weeks to diagnose the issue. With continuous automated monitoring in place, they estimated that such an error could be detected in a matter of hours, long before it causes major damage. The chart below illustrates this stark difference:
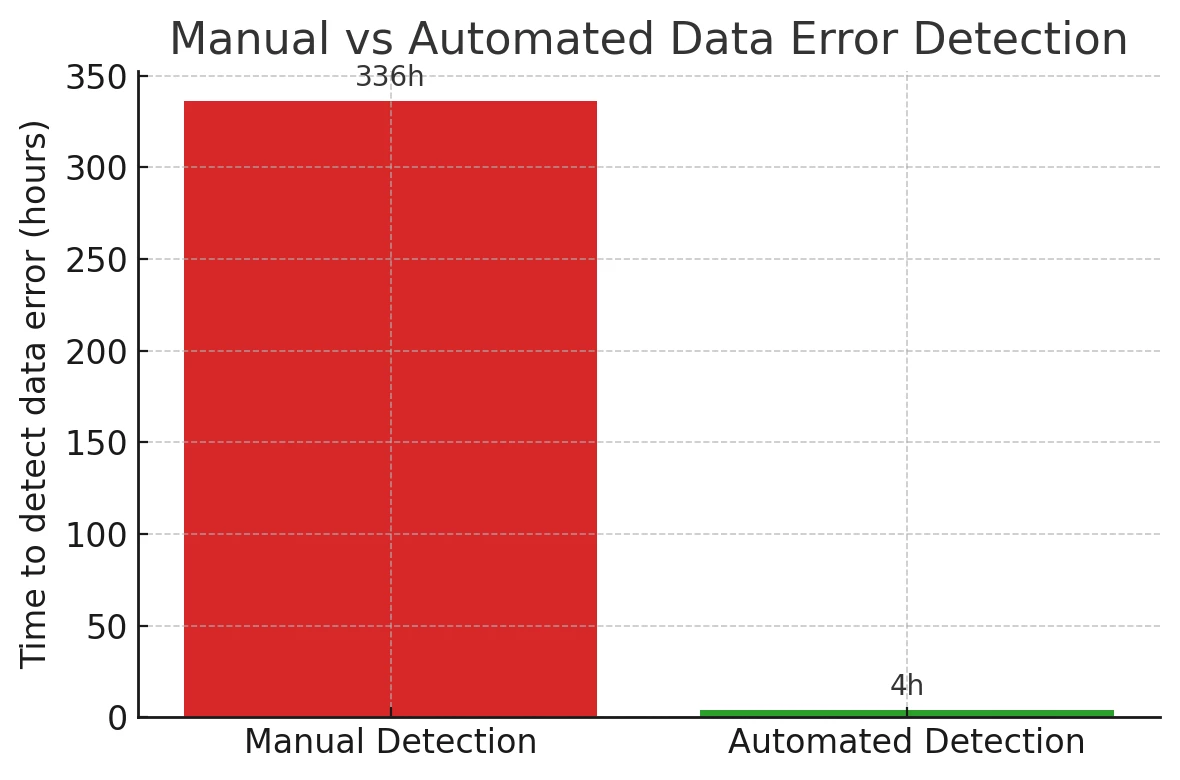
Speed and coverage are not just about IT metrics – they translate directly into business value. 100% data coverage means confidence that you’re not making decisions on a flawed subset of information. Catching an issue in 2 hours versus 2 weeks could be the difference between a minor hiccup and a multi-million dollar mistake. And when you multiply these improvements across dozens of data processes in an enterprise, the risk reduction and cost savings become very large. In fact, companies often find that improved data integrity reduces the downstream cost of errors and rework, and avoids the scenario of AI projects being abandoned due to “untrustworthy” results. Instead of AI systems delivering questionable outputs that users don’t trust, the AI begins to produce reliable insights, because it’s built on a foundation of vetted, high-quality data. This boosts user adoption of analytics and AI solutions – executives and frontline employees alike trust the dashboards, reports, or AI recommendations they’re given, because they know a robust validation framework stands behind them.
There’s also a regulatory and compliance benefit. Many industries (finance, healthcare, etc.) have strict data governance requirements. Continuous data integrity testing helps ensure you’re meeting those – for example, verifying data lineage and accuracy for SOX compliance or GDPR. It’s much easier to pass an audit when you can demonstrate automated controls that catch data issues and prove data accuracy across your SAP and related systems.
From a QA professional’s perspective, embracing data integrity testing is an opportunity to take quality ownership to the next level. It expands the role of QA beyond application functionality into the quality of data that fuels those applications and AI initiatives. This is a natural evolution – as one might say, quality is quality, whether it’s code or data. Testers already have the mindset and skills (like designing test cases, automation scripting, and results analysis) which can be applied to data scenarios. With the right tools, what used to be tedious (comparing spreadsheets or writing SQL by hand) can be automated and integrated into continuous testing pipelines. The outcome is not only a more AI-ready organization, but also a QA team that’s seen as a critical enabler of AI success rather than a bottleneck.
Conclusion: Clean Data Today, Smarter AI Tomorrow
In the era of AI and advanced analytics, ensuring data integrity has become as fundamental as ensuring your applications don’t crash. For enterprises running on SAP and similar complex systems, it’s the bridge between ambitious AI dreams and real, trusted AI outcomes. By investing in automated, continuous data quality practices, organizations set themselves up to fully capitalize on AI innovations – safely and confidently. Quality assurance professionals and testers have a pivotal role to play in this transformation. They are the guardians who can ensure that when the business asks, “Are we ready for AI?”, the answer is “Yes – our data is reliable and ready to fuel intelligent decisions.”
Bottom line: AI readiness isn’t just about algorithms and tools; it starts with clean, correct, and consistent data. Enterprises that recognize this – and empower their QA and data teams to guarantee it – will be the ones that truly thrive in the AI-powered future. Those that don’t will continue to find their AI projects stumbling over hidden data pitfalls. The choice is clear: prioritize data integrity now, and pave the way for AI-driven innovation.
This article is based on insights from the webinar “How data integrity can help enterprise SAP teams be AI-ready” To learn more and see these principles in action, be sure to check out the full webinar for a deeper dive into data integrity best practices and success stories.

