

This challenge is based on ECommerce test data because most of us SDETs should be familiar with E-commerce transactions (as customers). The given test dataset has customer details, product information, and e-commerce transactions. This dataset has multiple layers of relationships, data variety (such as customer tiers, product categories and payment statuses), and time-series data (such as customer signup dates and order dates). This data avoids personally identifiable information and is able to support multiple runs of realistic e-commerce automated scripted tests.
What is the challenge’s goal?
The goal of this challenge is for you to generate a larger synthetic dataset using AI techniques (for example generative AI or an AI model) or software scripting, while maintaining the relationships of the given original dataset. Your larger dataset should have the same schema (structure) as the original dataset. It should continue to have privacy (no personally identifiable information), data consistency, and variety.
Win conditions:
- You are given a small sample dataset. Download the Ecommerce_Retail_Dataset.zip. Refer the Ecommerce_Retail_Dataset Specifications section below for its specifications.
- Your goal is to generate a larger synthetic dataset using AI techniques, software scripting or tools (such as Mock Data Generator). The generated data should maintain the schema and relationships of the original data.
- Your dataset should be sufficient for large scale automated testing. Preferably, it should be between 10 times to 20 times the size of the given dataset.
- Once you complete your dataset, you should verify your dataset. Refer the Verification checks section below.
- You need to submit your answer. Refer How do you submit your answer section below for details.
- Your answer will be judged based on the match with the original dataset schema and relationships, data quality (realism, privacy, consistency and variety) and generated dataset size.
- The first three who finish this challenge correctly will receive a shareable certificate and a ShiftSync Giftbox (or Amazon 25 USD Gift card).
How do you submit your answer?
- Your answer should be the ZIP file (you should name it <yourname>.ZIP). Your ZIP file should contain 5 CSV (comma separated files), which are Customers.csv, Products.csv, Orders.csv, Order_Items.csv, and Payments.csv. Each file should contain the data of one table only. Send your CSV files attached to a message to me in LinkedIn at https://www.linkedin.com/in/inderpsingh/
- Add your comment in this post. You need to register and be a member of the ShiftSync community in order to comment, participate in the challenges and receive your prizes.
Note: If you do not comment, you will be disqualified from winning this challenge.
Challenge Details:
Ecommerce_Retail_Dataset Specifications
Table schema:
- Table: Customers (25 rows)
- Column Names:
- Customer_ID (Primary Key)
- Customer_Name
- Phone_Number
- Country
- Signup_Date
- Customer_Tier (values: Basic, Premium, Enterprise)
- Notes: The data values are synthetic for Customer_Name, Email, Phone_Number (e.g., "John Doe", "john.doe@example.com", "555-123-4567"). Consistency is maintained in formats for email and phone. The first 5 rows are:
- Column Names:
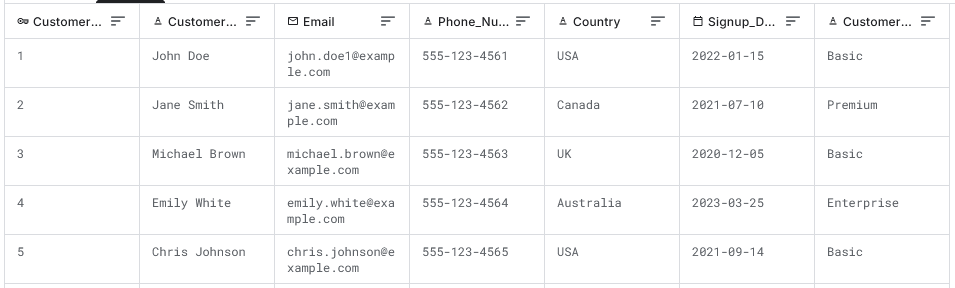
- Table: Products (10 rows)
- Column Names:
- Product_ID (Primary Key)
- Product_Name
- Category (values: Electronics, Clothing, Home Decor, Toys)
- Price
- Stock_Quantity
- Launch_Date
- Notes: Data should have a variety of products across categories. The first 5 rows are:
- Column Names:
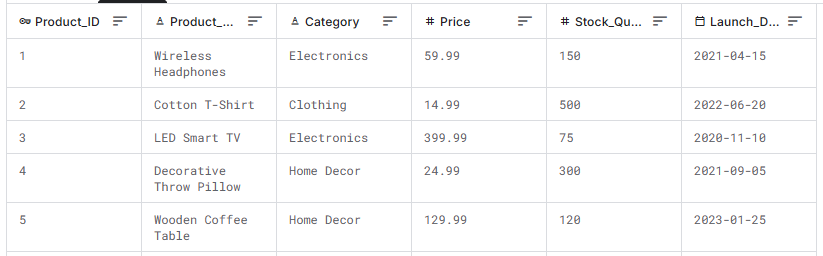
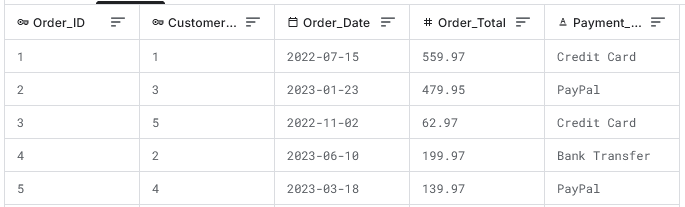
- Table: Orders (40 rows)
- Column Names:
- Order_ID (Primary Key)
- Customer_ID (Foreign Key referencing Customers)
- Order_Date
- Order_Total
- Payment_Method (values: Credit Card, PayPal, Bank Transfer)
- Notes: This table holds transactional data, which is linked to Customer_ID. The Order_Date values are spread over the past two years to implement time-series variability. The first 5 rows are:
- Column Names:
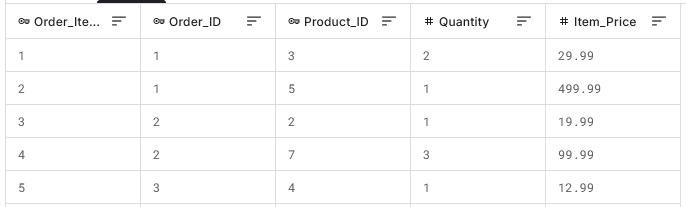
- Table: Order_Items (100 rows)
- Column Names:
- Order_Item_ID (Primary Key)
- Order_ID (Foreign Key referencing Orders)
- Product_ID (Foreign Key referencing Products)
- Quantity
- Item_Price
- Notes: An order can contain multiple items. There are multiple Order_Item_ID values (product combinations) for any Order_ID value (single value per order). The first 5 rows are:
- Column Names:
- Table: Payments (45 rows)
- Column Names:
- Payment_ID (Primary Key)
- Order_ID (Foreign Key referencing Orders)
- Payment_Date
- Payment_Amount
- Payment_Status (values: Completed, Failed, Pending)
- Notes: Payment status is linked to the corresponding Order_ID. 40 rows have Payment status value as Completed, 2 rows have Failed, and 3 rows have Pending value. The first 5 rows are:
- Column Names:
Format: Each table is stored in CSV format for easy integration with AI or scripting techniques. Each CSV file has the data of one single table only. There are 5 CSV files in total. They will be attached with this post.
- Table Relationships:
- Customers to Orders: One-to-Many relationship via Customer_ID. A customer can place multiple orders.
- Orders to Order_Items: One-to-Many relationship via Order_ID. An order can contain multiple items.
- Order_Items to Products: Many-to-One relationship via Product_ID. Multiple items in an order can refer to the same product.
- Orders to Payments: One-to-Many relationship via Order_ID. Each order can have one or more corresponding payments.
Verification Checks
- Verify no duplicity:
- No duplicate Customer_ID values
- No duplicate Product_ID values
- No duplicate Order_ID values
- No duplicate Order_Item_ID values
- No duplicate Payment_ID values
Sample Python code for automatically verifying no duplicity
import pandas as pd
import numpy as np
data_set_path = '...'
# Load dataset
customers = pd.read_csv(data_set_path + 'Customers.csv')
products = pd.read_csv(data_set_path + 'Products.csv')
orders = pd.read_csv(data_set_path + 'Orders.csv')
order_items = pd.read_csv(data_set_path + 'Order_Items.csv')
payments = pd.read_csv(data_set_path + 'Payments.csv')
# Check that there are no duplicate Primary Key values in any of the tables (Customer_ID, Product_ID, Order_ID, etc.).
# Function to check duplicates
def check_duplicates(df, primary_key):
if df[primary_key].duplicated().any():
print(f"Duplicate {primary_key} values found.")
else:
print(f"No duplicate {primary_key} values found.")
# Check each table for duplicate primary keys
check_duplicates(customers, 'Customer_ID')
check_duplicates(products, 'Product_ID')
check_duplicates(orders, 'Order_ID')
check_duplicates(order_items, 'Order_Item_ID')
check_duplicates(payments, 'Payment_ID')
- Cross-verify foreign key relationships:
- All Customer_ID in Orders exist in Customers.
invalid_customers = orders[~orders['Customer_ID'].isin(customers['Customer_ID'])]
if invalid_customers.empty:
print("All Customer_ID in Orders exist in Customers.")
else:
print(f"Invalid Customer_ID found in Orders:\n{invalid_customers}")
o All Order_ID in Order_Items exist in Orders.
invalid_order_items = order_items[~order_items['Order_ID'].isin(orders['Order_ID'])]
if invalid_order_items.empty:
print("All Order_ID in Order_Items exist in Orders.")
else:
print(f"Invalid Order_ID found in Order_Items:\n{invalid_order_items}")
- All Product_ID in Order_Items exist in Products.
invalid_products = order_items[~order_items['Product_ID'].isin(products['Product_ID'])]
if invalid_products.empty:
print("All Product_ID in Order_Items exist in Products.")
else:
print(f"Invalid Product_ID found in Order_Items:\n{invalid_products}")
- All Order_ID in Payments exist in Orders.
invalid_payments = payments[~payments['Order_ID'].isin(orders['Order_ID'])]
if invalid_payments.empty:
print("All Order_ID in Payments exist in Orders.")
else:
print(f"Invalid Order_ID found in Payments:\n{invalid_payments}")
- Check data integrity:
- For each order, Order_Total in Orders matches the sum of Order_Items Item_Price values.
order_items['Total_Item_Price'] = order_items['Item_Price'] * order_items['Quantity']
order_items_sum = order_items.groupby('Order_ID')['Total_Item_Price'].sum().reset_index()
# Merge with Orders to compare totals
orders_merged = orders.merge(order_items_sum, on='Order_ID')
# Set a small tolerance for floating-point comparison (epsilon = 1e-2)
epsilon = 1e-2
mismatch = orders_merged[~np.isclose(orders_merged['Order_Total'], orders_merged['Total_Item_Price'], atol=epsilon)]
if mismatch.empty:
print("Order_Total matches sum of Order_Items for all orders.")
else:
print(f"Order_Total mismatch found:\n{mismatch[['Order_ID', 'Order_Total', 'Total_Item_Price']]}")
- For each order, Payment_Amount in Payments matches with Order_Total in Orders.
# Payment Amount Consistency Check (Mapping Order_Total to Payment_Amount)
# Check that the grouped Payment_Amount (Completed or Pending) in the Payments table matches the Order_Total in the Orders table for the same Order_ID.
# Step 1: Filter payments to include only "Completed" and "Pending" statuses
filtered_payments = payments[payments['Payment_Status'].isin(['Completed', 'Pending'])]
# Step 2: Group by Order_ID and sum Payment_Amount
aggregated_payments = filtered_payments.groupby('Order_ID', as_index=False).agg({'Payment_Amount': 'sum'})
# Step 3: Merge aggregated payments with orders to compare Payment_Amount and Order_Total for each Order_ID
payments_merged = aggregated_payments.merge(orders[['Order_ID', 'Order_Total']], on='Order_ID')
# Step 4: Check for mismatches between aggregated Payment_Amount and Order_Total
payment_mismatch = payments_merged[payments_merged['Payment_Amount'] != payments_merged['Order_Total']]
# Step 5: Output the results
if payment_mismatch.empty:
print("Payment_Amount matches Order_Total for all payments.")
else:
print(f"Payment_Amount mismatch found:\n{payment_mismatch[['Order_ID', 'Payment_Amount', 'Order_Total']]}")



