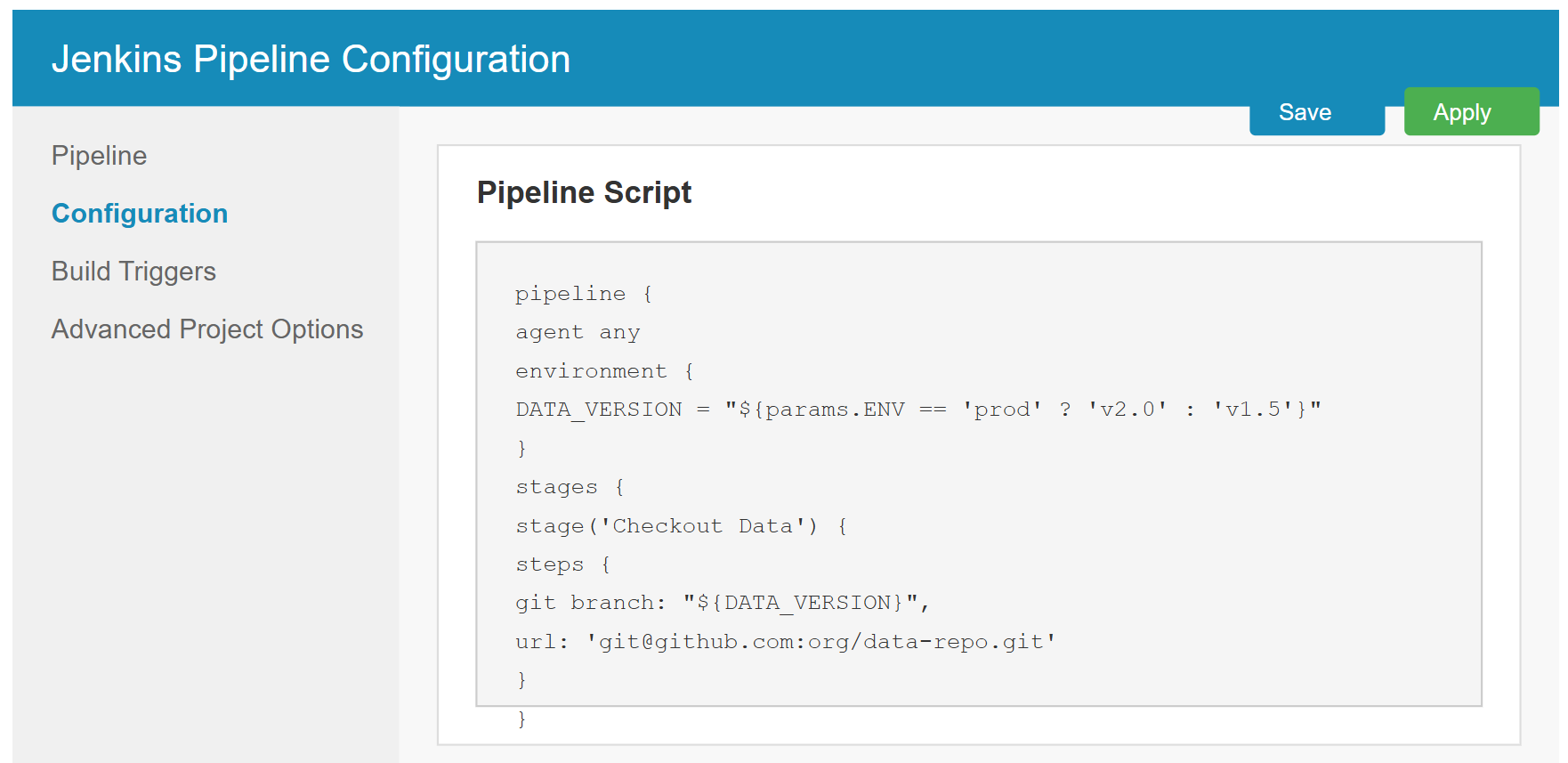
Task: Explore strategies for managing test data effectively in a DevOps environment. Implement one such strategy in your project.
-
Capture: A screenshot or description of your test data management approach.

 +2
+2Task: Explore strategies for managing test data effectively in a DevOps environment. Implement one such strategy in your project.
Capture: A screenshot or description of your test data management approach.
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.